Hadoop Summary
Hadoop
1. What is Hadoop
1) Hadoop 이란?
- 2006년 더그 커팅이 개발한 대용량 데이터 분산 처리 시스템
- 하나의 성능 좋은 컴퓨터 대신, 적당한 성능의 컴퓨터 여러 대를 클러스터로 묶고, 대용량 데이터를 클러스터에서 병렬로 동시 처리하여 처리 속도를 높이는 것을 목적으로 한다.
2) HDFS - 데이터 분산 저장


- MasterNode
- Namenode
- Datanode의 정보를 저장하는 메타데이터를 담고 있음.
- 메타데이터는 fsimage와 editlog로 나뉨
- fsimage는 네임스페이스와 블록 정보를 나타냄
- editlog는 파일의 생성, 삭제에 대한 트랜잭션
- Datanode는 Namenode에게 Hearbeats를 보낸다.
- 이 때, Heartbeats는 디스크 가용 공간정보, 데이터이동, 적재량 등을 가짐
- 10초 이상 Heartbeats가 없으면 해당 Datanode를 불가용 노드로 취급
- (참고) Secondary Namenode
- Namenode 구동 후, 변경 내역이 담긴 editlog가 빈번하게 생성됨
- 이러한 과정은 디스크 부족 문제 및 재구동 시간에 영향을 끼침
- Secondary Namenode는 Fsimage와 editlog를 주기적으로 mege하여 최신 블록 상태의 파일을 생성

- Namenode
- SlaveNode
- Datanode
- 실제 데이터들이 저장되는 공간
- block단위로 저장되며 한 block당 default 128MB
- block은 replictaion factor 갯수 만큼 복제된다.
- Datanode
NameNode 구동 과정
1) fsimage를 읽어 메모리에 적재
2) Edits 파일을 읽어와서 변경 내역을 반영
3) 현재의 메모리 상태를 Snapshot으로 생성하여 FsImage 파일 생성
4) Datanode로 부터 블록 리포트를 수신하여 맵핑정보 생성
5) 서비스 시작
파일 읽기
1) Namenode에 파일이 보관된 블록 위치 요청
2) Namenode가 블록 위치 반환
3),4),5) 각 데이터 노드에 파일 블록을 요청 (만약, 노드 블록이 손상되었다면 Namenode에 이를 통지하고 다른 블록 확인)

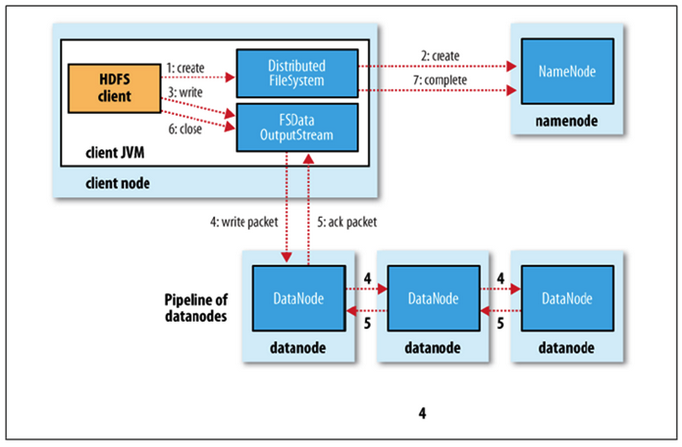
파일 쓰기
1) Namenode에 파일정보를 전송하고, 파일의 블록을 써야할 노드 목록 요청
2) Namenode가 파일을 저장할 목록 반환
3) Datanode에 파일 쓰기 요청
4),5) Datanode간 replica 진행
6) 종료
7) Datanode의 메타정보가 Namenode에게 전달되어 갱신
참고 : https://wikidocs.net/23582
- Hadoop High Availabilty
- Hadoop 2.x 이후부터는 Standby Namenode 개념이 등장한다
- 현재 작동 중인 Active Namenode가 예기치 못하게 종료될 경우, 대기 중이던 Standby Namenode가 Active역할을 이어받는다
- Hadoop 3.x 이후부터는 Standby Namenode 다수 설정이 가능하다

1) JournalNode :
- editlog를 자신이 실행되는 서버의 로컬디스크에 저장
- Namenode는 클라이언트가 되어서 JounalNode에게 접근해 저장을 요청
- Active Namenode만 editlog 저장권한이 있고, Standby node는 조회만 가능
2) Zookeeper :
- Namenode HA상태 정보를 저장하는 장소
- 어떤 서버가 Active인지 Standby인지 저장
3) ZookeeperFailverController
- 로컬 Namenode의 상태를 모니터링
- 자동 Failover : Active Namenode에 장애가 발생하면 감지해서 자동으로 ZKFC와 Zookeeper 마스터 간의 세션 종료 → Standby Namenode를 Active Namenode로 전환 → 기존의 Active Namenode 제거
4) QJM(QuormJounalManager)
- Namenode 내부에 있는 QJM이 Journal Node에 editlog 출력
- Active Namenode만 Journal Node에 editlog write 가능
- Standby Namenode는 Jounral Node에서 editlog를 조회하고 fsimage 갱신
Hadoop HA 출처 : https://dabingk.tistory.com/7
3) MapReduce - 데이터 처리 연산
- MasterNode
- JobTracker : 클라이언트가 요청한 App에 대해 전체적인 Job의 흐름을 관리하고 감독한다
- SlaveNode
- TaskTracker : JobTracker로부터 받은 Job을 실제로 수행하고, JobTracker와 통신하여 상태를알린다.

- MapReduce WordCount 예제
- Input : 데이터를 삽입
- Splitting : Row 별로 데이터를 나눔
- Mapping : 각 단어 별로 갯수 1을 할당하여 Key:Value 형식으로 변환
- Shuffling : 같은 Key별로 모음
- Reducing : 최종적으로 해당 Key의 value들의 합(단어 빈도수)을 구한다

참고 : https://wikidocs.net/30235
4) YARN - 자원 관리 매니저 (Hadoop v2.x 이후 등장)
(Yet Another Resource Negotiator)
- MasterNode
- ResourceManager
- 클러스터에 1개 존재하며, 클러스터의 전반적인 자원 관리를 담당
- 클라이언트로부터 App 실행 요청을 받으면, 그 실행을 책임질 App Master를 실행
- 클러스터 내의 Node Manager들과 통신하여, 할당된 자원과 사용 중인 자원 상황 인식
- Scheduler
- NodeManager들의 자원 상태를 관리하며 부족한 리소스를 할당
- 자원 상태에 따라서 태스크들의 실행 여부를 허가해주는 스케쥴링 작업만 담당
- NodeManager들의 자원 상태를 Resource Manager에게 통보
- ApplictaionManager
- Node Manager에서 특정 작업을 위해 Applictaion Manager를 실행하고, Application의 실행 상태를 관리하여 그 상태를 Resource Manager에게 통지
- ResourceManager
- SlaveNode
- NodeManager
- 노드 당 한개씩 존재하며, Container의 리소스 사용량을 모니터링
- 또한, 관련 정보를 Resource Manager에게 알림
- Container
- CPU, Disk, Memory 등의 리소스를 일컫는다
- 모든 Job은 여러 개의 Task를 세분화되고, 각 Task는 각 Container에서 실행
- 필요한 자원 요청은 App Master가 담당하고, 승인은 Resource Manager가 담당
- AppMaster
- YARN에서 실행되는 하나의 Task를 관리하는 마스터 서버. App당 1개가 존재
- Scheduler로 부터 적절한 Container를 할당 받고, 프로그램 실행 상태를 모니터링
- NodeManager

1) YARN 클라이언트가 제출하는 Job App이 RM에게 제출이 된다
2) Application Manager는 Job의 유효성을 확인하고, 자원 할당을 위해 Scheduler 에게 넘김
3) Scheduler는 임의 Slave Node 내의 Container 중 하나를 App Master로 할당
4) AppMaster는 slave node 상의 데이터의 위치, 리소스 등을 RM에게 알려 AppMaster 외의 Container 들을 조율
5) RM은 최상의 리소스들을 할당하고, AppMaster에 node의 디테일한 정보를 전달
6) AppMaster는 Container들을 실행시키기 위해, slave node 상의 NodeManager에게 요청
7) AppMaster는 Job이 실행되는 동안, 요청된 Container들의 리소스를 관리하고, 실행이 완료되면 RM에게 통보
8) NodeManager는 Scheduler가 새로운 app 시작이 가능하도록, 주기적으로 자신의 노드에서 현재 이용가능한 리소스 상태를 RM에게 알린다
9) Slave node에서 이상이 생기면, RM은 AppMaster가 프로세스를 완료할 수 있도록 새 Container를 할당
참고 : https://opentutorials.org/module/2926/17248
2. Hadoop Installation
1) Hadoop Standalone (20220603 기준, CentOS 8)
CentOS 8 이미지 pull
1
2
$ docker pull centos
$ docker run -itd --name hadoop-base centos
필요 패키지 설치
1
2
3
4
5
6
7
8
# CentOS 컨테이너 내부(아래 sed 2개 명령어는 centos8일때만. centos8 EOS로 인해 Mirror site를 못잡아서 임의로 함)
# https://chhanz.github.io/linux/2022/02/04/dnf-error-centos-8/
$ sed -i 's/mirrorlist/#mirrorlist/g' /etc/yum.repos.d/CentOS-Linux-*
$ sed -i 's|#baseurl=http://mirror.centos.org|baseurl=http://vault.centos.org|g' /etc/yum.repos.d/CentOS-Linux-*
$ yum update
$ yum install wget -y
$ yum install vim -y
JAVA 설치
1
2
$ yum install java-1.8.0-openjdk-devel.x86_64 -y
$ java -version

환경변수 설정
1
2
3
4
$ which java
/usr/bin/java
$ readlink -f /usr/bin/java
/usr/lib/jvm/java-1.8.0-openjdk-1.8.0.312.b07-2.el8_5.x86_64/jre/bin/java

1
2
3
4
5
$ vim ~/.bashrc
export JAVA_HOME=/usr/lib/jvm/java-1.8.0-openjdk-1.8.0.312.b07-2.el8_5.x86_64
export PATH=$PATH:$JAVA_HOME/bin
export JAVA_OPTS="-Dfile.encoding=UTF-8"
export CLASSPATH="."
Hadoop 설치
1
2
3
4
5
6
# Hadoop 홈 디렉토리로 사용할 디렉토리 설정
$ mkdir /hadoop_home
$ cd /hadoop_home
# hadoop 다운로드 후 tar (20220603 기준, hadoop-3.3.3 최신)
$ wget https://dlcdn.apache.org/hadoop/common/hadoop-3.3.3/hadoop-3.3.3.tar.gz
$ tar -xvzf hadoop-3.3.3.tar.gz
1
2
3
4
5
6
7
8
9
$ vim ~/.bashrc
export JAVA_HOME=/usr/lib/jvm/java-1.8.0-openjdk-1.8.0.312.b07-2.el8_5.x86_64
export PATH=$PATH:$JAVA_HOME/bin
export JAVA_OPTS="-Dfile.encoding=UTF-8"
export CLASSPATH="."
# 여기서부터 하둡 설정내용
export HADOOP_HOME=/hadoop_home/hadoop-3.3.3
export HADOOP_CONFIG_HOME=$HADOOP_HOME/etc/hadoop
export PATH=$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbin
1
$ source ~/.bashrc
1
2
3
4
5
6
7
$ hadoop version
Hadoop 3.3.3
Source code repository https://github.com/apache/hadoop.git -r d37586cbda38c338d9fe481addda5a05fb516f71
Compiled by stevel on 2022-05-09T16:36Z
Compiled with protoc 3.7.1
From source with checksum eb96dd4a797b6989ae0cdb9db6efc6
This command was run using /hadoop_home/hadoop-3.3.3/share/hadoop/common/hadoop-common-3.3.3.jar
MapReduce 사용
1
2
3
$ hadoop jar $HADOOP_HOME/share/hadoop/mapreduce/hadoop-mapreduce-examples-3.3.3.jar wordcount \
$HADOOP_HOME/LICENSE.txt wordcount_output
$ ls -l

1
2
3
4
5
6
7
8
9
10
11
$ head -10 wordcount_output/part-r-00000
"AS 2
"Contribution" 1
"Contributor" 1
"Derivative 1
"Legal 1
"License" 1
"License"); 1
"Licensor" 1
"NOTICE" 1
"Not 1

참고 : https://mungiyo.tistory.com/16
2) Hadoop Docker Image
1
2
$ git clone [https://github.com/big-data-europe/docker-hadoop.git](https://github.com/big-data-europe/docker-hadoop.git)
$ docker-compose up -d
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
version: "3"
services:
namenode:
image: bde2020/hadoop-namenode:2.0.0-hadoop3.2.1-java8
container_name: namenode
restart: always
ports:
- 9870:9870
- 9000:9000
volumes:
- hadoop_namenode:/hadoop/dfs/name
environment:
- CLUSTER_NAME=test
env_file:
- ./hadoop.env
datanode:
image: bde2020/hadoop-datanode:2.0.0-hadoop3.2.1-java8
container_name: datanode
restart: always
volumes:
- hadoop_datanode:/hadoop/dfs/data
environment:
SERVICE_PRECONDITION: "namenode:9870"
env_file:
- ./hadoop.env
resourcemanager:
image: bde2020/hadoop-resourcemanager:2.0.0-hadoop3.2.1-java8
container_name: resourcemanager
restart: always
environment:
SERVICE_PRECONDITION: "namenode:9000 namenode:9870 datanode:9864"
env_file:
- ./hadoop.env
nodemanager1:
image: bde2020/hadoop-nodemanager:2.0.0-hadoop3.2.1-java8
container_name: nodemanager
restart: always
environment:
SERVICE_PRECONDITION: "namenode:9000 namenode:9870 datanode:9864 resourcemanager:8088"
env_file:
- ./hadoop.env
historyserver:
image: bde2020/hadoop-historyserver:2.0.0-hadoop3.2.1-java8
container_name: historyserver
restart: always
environment:
SERVICE_PRECONDITION: "namenode:9000 namenode:9870 datanode:9864 resourcemanager:8088"
volumes:
- hadoop_historyserver:/hadoop/yarn/timeline
env_file:
- ./hadoop.env
volumes:
hadoop_namenode:
hadoop_datanode:
hadoop_historyserver:
⇒ localhost:9870 (Namenode Web UI)


3) Apache Bigtop
참고 : https://snowturtle93.github.io/posts/Apache-Bigtop을-이용한-Ambari-설치-및-Hadoop-클러스터-구축/
maven 설치 : https://kabby91.tistory.com/8
환경 : Docker Desktop 환경, 이미지는 centos:centos7 이미지를 사용
시도1 :
- yum update시 사전작업
CentOS 8 EOS로 인해 Mirror site 가 vault 로 전환되어 Mirror site를 못 찾아 발생되는 문제
1 2
$ sed -i 's/mirrorlist/#mirrorlist/g' /etc/yum.repos.d/CentOS-Linux-* $ sed -i 's|#baseurl=http://mirror.centos.org|baseurl=http://vault.centos.org|g' /etc/yum.repos.d/CentOS-Linux-*
- Centos8(최신버전), maven 3.8.5(최신버전) 시도했으나,
./gradlew task ambari-pkg(ambari-rpm)에서 진행률 71% 이후로, 넘어가지를 않음 (무한 반복 인건지, 아니면 설치할 것이 많은 것인지 모르겠음. 최대 1시간 10분을 기다려도 빌드완성이 안됨)
시도2 :
- Centos7, maven 3.6.3 시도했으나
여전히, 진행률 71% (ambari-rpm) 이후로 20분, 30분이 경과해도 빌드 진행 중

아래 화면에서 30분, 40분 경과해도 더 이상 진행이 안됨

그 외 : 해당 rpm 패키지도 존재하지 않음

시도 3 :
Bigtop을 이용한 Hadoop 설치 (2022.06 Standalone)
3. Hadoop Command (dfs 커맨드)
1) 파일 목록
1
2
# 최상위 디렉터리에서의 파일목록
$ hdfs dfs -ls /

2) 디렉터리 생성
1
2
# 최상위 디렉터리에서 mydir란 이름의 디렉터리 생성
$ hdfs dfs -mkdir /mydir
3) hdfs put
1
2
3
4
# 로컬 파일을 hdfs에 write하기
$ echo "hello, world" >> test.txt
$ hdfs dfs -put test.txt /mydir
$ hdfs dfs -ls /mydir

4) hdfs get
1
2
3
4
5
6
7
8
9
10
11
12
$ rm test.txt
$ hdfs dfs -get /mydir/test.txt
$ hdfs dfs -ls /mydir
Found 1 items
-rw-r--r-- 3 hdfs hadoop 13 2022-06-06 05:29 /mydir/test.txt
$ ls -l
total 32
drwxrwxrwt 2 hdfs hadoop 4096 Sep 10 2017 cache
-rw-r--r-- 1 hdfs hdfs 20628 Jun 6 02:12 nn.format.log
-rw-r--r-- 1 hdfs hdfs 13 Jun 6 05:33 test.txt
$ cat test.txt
hello, world

- 그 외의 dfs 명령어들

https://hadoop.apache.org/docs/r2.4.1/hadoop-project-dist/hadoop-common/FileSystemShell.html